새롭게 알게된 것
- [[gem5]]
다운로드
- simplessd 공홈
- 하라는 대로 하면 된다. (FullSystem은 example 을 실행해도 그대로 안되서, 그냥 standalone 을 먼저 봐보기로 했다.)
문서 읽기
- 그냥 홈페이지에 있는 문서를 읽어보자. 중요하니까 정리해놨겠지
그림으로 그려보기
-
Host Interface Layer
- HIL 이라고도 불리는 Host Interface Layer에 대한 설명이다.
- HIL 은 host side에 있는 host controller, host controller 에게 추상화된 API를 제공해주는 SSD Interface
Host Controller
- NVMe, SATA and UFS를 구현해 놓았으며, Open-Channel SSD 는 NVMe 를 상속받음.
Host Interface
hil/nvme/interface.hh에SimpleSSD::DMAInterface를 상속하여 선언된SimpleSSD::HIL::NVMe::Interface를 보자.
class DMAInterface {
public:
DMAInterface() {}
virtual ~DMAInterface() {}
virtual void dmaRead(uint64_t, uint64_t, uint8_t *, DMAFunction &,
void * = nullptr) = 0;
virtual void dmaWrite(uint64_t, uint64_t, uint8_t *, DMAFunction &,
void * = nullptr) = 0;
};
class Interface : public SimpleSSD::DMAInterface {
protected:
Controller *pController;
public:
virtual void updateInterrupt(uint16_t, bool) = 0;
virtual void getVendorID(uint16_t &, uint16_t &) = 0;
};
DMAInterface에서는 Direct Memory Access 를 위해서dmaRead,dmaWrite를 제공한다.updateInterrupt는 host의 특정 interrupt vector 에 interrupt를 보낸다.getVendorId는 NVMe의Identify Controller가 vendor Id와 subsystem vendor ID를 필요로 하기 때문에 존재하는 method 이다.
Controller and Firmware
- NVMe controller/firmware 는 아래 3가지 컴포넌트 (Controller, Subsystem and Namespace)로 구성된다.
- Controller는 모든 queue 연산(SQ 에서 request 를 읽고, CQ에 request를 쓰고, 인터럽트를 발생시키는)을 담당한다.
- Subsystem은 모든 NVMe의 admin commands를 다루며, Namespace를 제어하고, SSD Layer에 I/O를 실행한다.
- Namespace는 모든 NVMe의 I/O commands 를 다룬다.
Controller
- 모든 queue 연산을 담당하는 Controller는
hil/nvme/controller.hh에SimpleSSD::HIL::NVMe::Controller로 정의되어 있다. EventEngine은 주기적으로Controller::work를 유발시키며, 이때 주기는WorkPeriod설정값을 참조한다.Controller::work는 설정된 중재 함수(Controller::collectSQueue)를 사용하여 모든 submission queue를 모은다.-
새로운
Request는 내부의 FIFO Queue(Controller::lSQFIFO) 에 넣어지며, 새로운 Request 가 있다면,Controller:handleRequest를 호출해야 한다. 이때 이 함수는AbstractSubsystem::submitReqeust를 유발한다. AbstractSubsystem이 request를 처리하고 난 뒤,Controller::submit함수가 불려지게 되며, 내부적으로 존재하는 FIFO Queue(Controller::lCQFIFO)에 완료된 걸 넣는다.Controller::submit함수는Controller::completion함수를 부르는 event를 관리한다.Controller::completion함수는 CQ entry를 채우고,Controller::updateInterrupt를 사용해서 interrupt를 보낸다.Controller::updateInterrupt는 단순히Interface::updateInterrupt를 호출한다.
Subsystem
- admin commmands를 다루는 NVMe Subsystem은
hil/nvme/subsystem.hh에SimpleSSD::HIL::NVMe::Subsystem으로 선언되어 있다. - Open-channel SSD Subsystem은
hil/nvme/ocssd.hh에SimpleSSD::HIL::NVMe::OpenChannelSSD로 선언되어 있다. - 두 subsystem 모두
hil/nvme/abstract_subsystem.hh의SimpleSSD::HIL::NVMe::AbstractSubsystem을 상속한다. -
기본적으로 아래쪽 설명들은 NVMe subsystem 을 기반으로 하고 있는데, Open-Channel SSD 랑 사소한 차이만 있기 때문이다.
- NVMe Subsystem은 2부분으로 나뉘는데, command handling, I/O request handling.
-
Subsystem이 여러 namespaces를 가질수 있으므로, Subsystem은 반드시 I/O requests 를 Namespaces 로부터 HIL의 SSD Interface로 넘겨줘야 한다.
- 각 NVMe 명령들은
- I/O 명령이라면,
Subsystem::submitCommand함수를 통해서 특정한 Namespace로 가지게 되며. - 관리용(admin) 명령이라면,
submitCommand함수는 OPCODE를 확인한 이후 적절한 함수를 호출하게 된다.
- I/O 명령이라면,
-
모든 명령들은 완료됨을 알리기 위해서
Controller::submit를 유발한다. -
특정한 I/O 함수들(
Subsystem::read, write, flush and trim)이 불리게 된다면, I/O unit으로 번역된뒤, SSD Intreface의 함수들로 간다. (HIL::HIL::read,HIL::HIL::write,HIL::HIL::flushandHIL::HIL::trim); - SSD를 선형적으로 쪼개기 위해서, Subsystem은 multiple Namespaces를 유지한다.
- 예를 들어 1TB SSD 가 4K 논리적 block을 사용한다고 하자. 이때 512GB, 256GB, 256GB 용량으로 3개의 Namespaces로 쪼갤수 있다.
- Subsystem은 offset과 length를 찾아서 namespaces를 할당할 것이고, Subsystem은 할당되지 않은 공간을 처음 맞는 Namespaces에 할당한다.(first-fit). 만약 공간이 없다면 할당이 실패한다.
- 각 Namespace 마다 offset과 length를 가지고 있으며, 이 값은 SSD interface를 위해 I/O unit으로 번역될때 쓰인다.
Namespace
- I/O 명령을 다루는 NVMe Namespace는
hil/nvme/namespace.hh에SimpleSSD::HIL::NVMe::Namespace로 선언되어 있으며. NVMe Subsystem과 비슷한 구조를 다룬다.(둘다 command를 다룬다.) - I/O 명령이 오면, Namespace 는 Subsystem의 해당 함수들을 호출한다.(
read,write,flushandtrim).
Serial AT Attachment
- Serial AT Attachment - SATA 는 SSD와 HDD를 위한 전통적 interface이다.
- SimpleSSD 에서는 Serial ATA Advanced host Controller Interface (AHCI) 1.3.1 에 기반한 STATA HBA를 구현하였고, Serial ATA Revision 3.0 에 기반을 둔 STAT PHY와 프로토콜을 구현하였다.
Host interface
hil/sata/interface.hh에 선언된SimpleSSD::HIL::SATA::Interface추상 클래스는 simulator에게 common API를 제공한다.-
SimpleSSD-FUllSystem 에서
src/dev/storage/sata_interrface.hh에 선언된SATAInterface에서 어떻게 상속하는지 확인할 수 있다. SimpleSSD::HIL::SATA::Interface은 오직virtual void updateInterrupt(bool) = 0를 interrupt posting 을 위해서 포함하고 있다.
Host Bus Adapter
- SATA는 Host Bus Adapter(HBA) 라고 불리는 host sid controller 를 필요로 한다.
-
HBA 디자인은 다양하지만, 우리는 누구나 접근할수 있는 AHCI spcification을 사용했다.
-
우리는 단 하나의 SimpleSSD 인스턴스만 HBA에 연결되기 때문에 단 하나의 port 만 구현했다.
Interface는 AHCI registser(Genetic Host Controller registers and Port registers)를HBA::writeAHCIRegister함수를 통해서 쓴다.PxClregister에 bits를 쓰는 건 그에 대항하는 NCQ에 새로운 요청이 있다는걸 의미한다.-
HBA는 내부 FIFO(HBA::lRequestQueue)에 request를 넣기 위해서HBA::processCommand를 호출한다. -
NVMe와 동일하게 Event Engine은 주기적으로
HBA::work함수를 호출하고, 이 함수는HBA::handleRequest함수를 호출하고와Device::submitCommand함수가 불리게 된다. - command handling 이후
Device는HBA::submitFIS함수를 FIS 응답을 host에게 돌려주기 위해서 부른다.HBA::submitFIS함수는HBA::lResponseQueue에 응답을 넣고,HBA::handleResponse함수를 호출하는 event를 예약한다.handleResponse함수는 내부의 FIFO에서부터 첫번째 response를 읽고, NCQ에 써서Interface::updateInterrupt함수를 사용해 Interrupt를 보낸다.
Device
hil/sata/device.hh에 선언된SimpleSSD::HIL::SATA::Device는 HBA와 연결하는 Device이다.- Device는 아래 나열된 ATA 명령어(ATA/ATAPI Command Set -2 (ACS-2) 와 (AT Attachment 8 - ATA/ATAPI Command Set (ATA8-ACS))를 다룰수 있다.
FLUSH CACHEFLUSH CACHE EXTIDENTIFY DEVICEREAD DMAREAD DMA EXTREAD FPDMA QUEUEDREAD SECTORREAD SECTOR EXTREAD VERIFY SECTORREAD VERIFY SECTOR EXTSET FEATUREWRITE DMAWRTIE DMA EXTWRITE FPDMA QUEUEDWRTIE SECTORWRTIE SECTOR EXT
- Device 의 구현이 NVMe Subsystem에 비해 간단해 보일수 있는데, 이는 Namespace를 관리할 필요가 없기 때문이다.
- 모든 명령어들은
Device::submitCommand함수를 통과하며 적절하게 다루어진다. - 완료 이후, 각 명령어들은 명령의 결과를
HBA에게 보고하기(report) 위해서HBA::submitFIS를 호출한다. - I/O 와 관련된
READ*,WRITE*andFLUSH*는 SSD Interface의 함수 (HIL::HIL::read, write and flush) 를 호출한다.
Universal Flash Storage
- Universal Flash Storage - UFS : 모바일용 저장소를 위해 디자인된 interface. 대부분의 스마트폰들이 이 UFS interface를 사용하고 있다.
- SimpleSSD 에서는
Universal Flash Storage (UFS) Host Controller Interface (JESD223)을 기반으로 UFS Host Controller를 구현하였으며, UFS PHY는Specification for M-PHY Version 4.0을, UFS protocol은Universal Flash Storage (UFS) Version 2.1 (JESD220C)를 기반으로 한다.
Host Interface
SimpleSSD::HIL::UFS::Interface는 simulator에게 common API를 제공하기 위해 추상 클래스로hil/ufs/interface.hh에 정의되어 있다. 어떻게 구체화 하는지는 SimpleSSD_FullSystem의UFSInterface는scr/dev/storage/ufs_interface.hh에 나와 있다.SimpleSSD::HIL::UFS::Interface는 단지generateInterrrupt()와clearInterrupt()를 포함한다.
Host Controller inteface
- SATA처럼 UFS도 UFS Host Controller Interface - UFSHCI 를 제공한다. 이 인터페이스는
Universal Flash Storage (UFS) Host Controller Interface (JESD223)를 따라간다. -
UFSHCI 는
hil/ufs/host.hh에SimpleSSD::HIL::UFS::Host로 구현되어 있다. Interface는 UFSHCI register에Host::writeRegister함수를 사용해서 쓴다.- UFS는 3가지 종류의 명령이 있는데
- UFS Trasnport Protocol Transfer (UTP Transfer)
- UFS Transport Protocol Task Management (UTP Task)
- UFS InterConnect Command (UIC Command)
- 각 명령어들은 request를 알리는데 서로 다른 doorbell을 사용하며
REG_UTRLDBR는 UTP TransferREG_UTMRLDBR는 UTP TaskREG_UICCMDR는 UIC Command
-
를 확인할때 사용할수 있다.
- 리눅스 커널과 UFS 2.1에서 UTP Task는 구현되지 않았기 때문에 SimpleSSD 에서도 구현하지 않았다.
- UIC Commands 는 오직 UFS hardware를 초기화 할때만 사용하며(M-PHY link 부팅 등), 그러므로 우린 오직 2가지 기초적 명령어들만 구현했다.
-
NVMe와 SATA처럼 Event Engine 은 주기적으로
Host::work함수를 호출하며.Host::handleRequest함수는work에 의해서 호출되고 request가 유효한지를 검증한다.Host::processUTPCommand는 request를 파싱하고, request에 적합한 handler를 부른다. - UFS Transfer는 3가지 유형의 명령어들로 정의된다.
- Command (SCSI protocol)
- Native UFS Command
- Device Management Command
-
Native UFS Command는 UFS 2.1 에서 정의되지 않았기 때문에 우린 Command 와 Device Management Command 만을 구현했다.
Device::processCommand함수는 Command 를 다루고Device::processQueryCommand함수는 Device Management Command 를 다룬다.handleRequest함수에서 완료 루틴(Completion routine) 이 선언되어 있으며 이는doRequest와doWrite라는 lambda 함수들을 확인하면 된다.doWrite함수는 completion routine(Host::completion)을 예약하며,completion함수는Interface::updateInterrupt함수를 사용해서 Interrupt를 보낸다.
Device
- UFSHCI 와 연결해주는 Device 는
hil/ufs/device.hh에SimpleSSD::HIL::UFS::Device를 정의한다. - UFS 는 SCSI commands set(
SCSI Block Commands - 3 (SBC-3)와SCSI Primary Commands - 4(SPC-4)) 을 I/O 하기 위해서 사용gksek. - Device 는 아래 나오는 SCSI 명령어들로 다루어진다.
INQUERYMODE SELECT 10MODE SENSE 10READ 6READ 10READ CAPACITY 10READ CAPACITY 16START STOP UNITTEST UNIT READYREPORT LUNSVERIFY 10WRITE 6WRITE 10SYNCHRONIZE CACHE 10
- Device 의 구현은 SATA와 비슷하지만 2가지 명령어 handling 함수를 가진다. (
processCommand와processQueryCommand) - 완료 이후 각 SCI command 함수는 callback handler 를 호출하며, 이때
processCommand함수의 인자로서 콜백은 제공한다. processQueryCommand는 즉시 결과를 리턴한다. I/O 관련 명령READ*,WRITE*와SYNCHRONIZE CACHE는 SSD Interface 함수들 (HIL::HIL::read, write and flush) 를 호출한다.
nvme 소스코드와의 비교
- [[nvme]] 페이지에 나름 정리한걸 올려놨다.
- driver 부분을 주로 비교하고 나머진 아직 openssd 를 읽으면서 해야할듯.
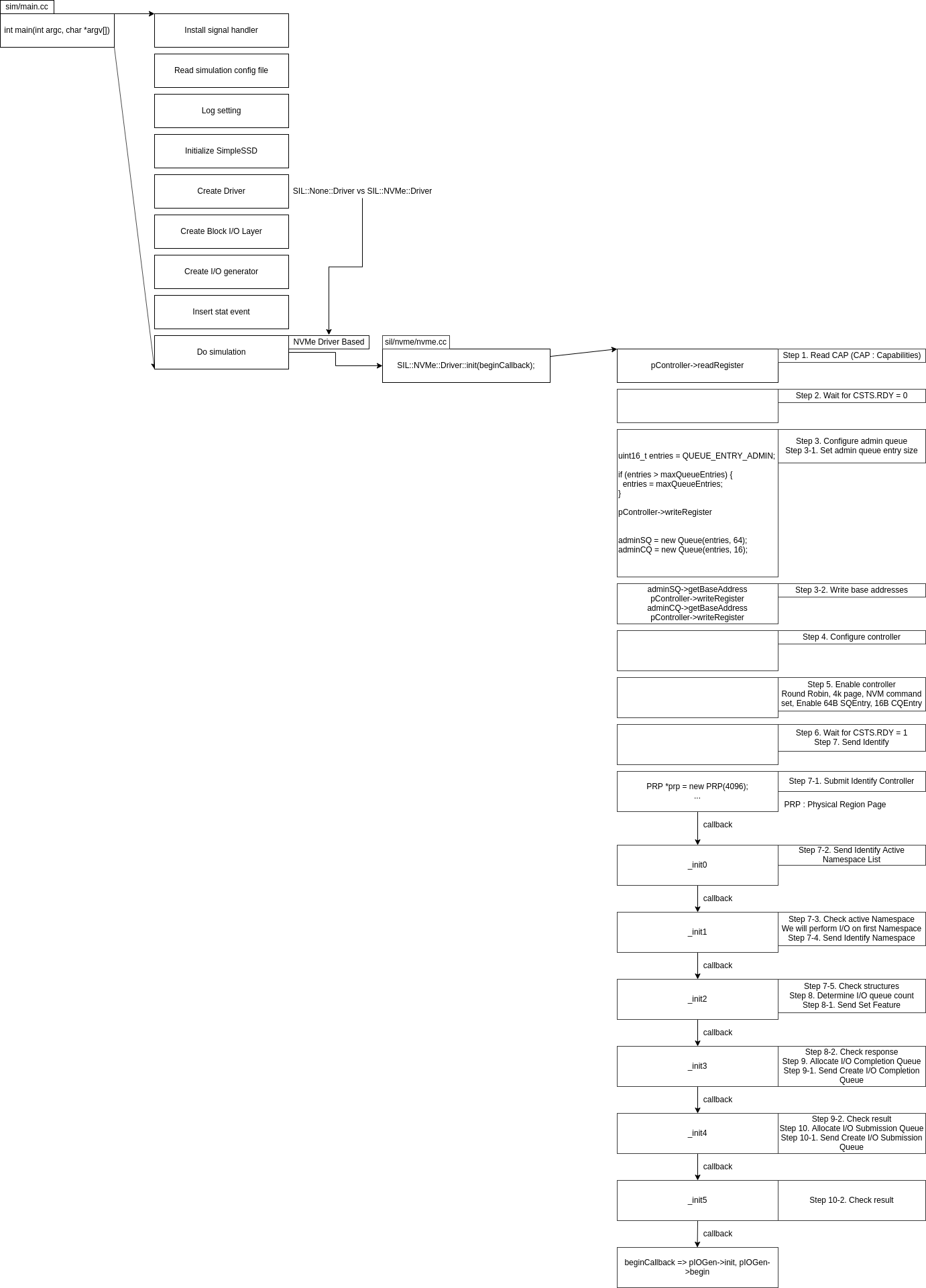
프로그램 시작점
- simplessd에서
sim/main.cc파일의 220번째 줄을 보면RequestGenerator가 있다. 여기서submitIO()가 bio를 호출 (실제로는 시뮬레이션이지만, 편의상)하고,iocallback()이 주기적으로rescheduleSubmit()를 호출하면서 IO를 발생시킨다. - 여기서는
bil/interface.hh에DriverInterface를 만들어 두어서BIOlayer를 구현해둔듯 하다. scheduler는 단순히DriverInterface의submitIO를 호출하는게 전부임.
BIO 발생 -> 드라이버
request로부터 opcode 분리
- linux 의
drivers/nvme/host/core.c의nvme_queue_rq()에서 호출하는nvme_setup_cmd()와 SimpleSSD의sil/nvme/nvme.cc의Driver::submitIO()가 서로 같은 일을 하고 있음. - 명령어의 종류에 따라 (
READ,WRITE,TRIM(DISCARD),FLUSH) 기본적인 setup과정을 호출해준다.SimpleSSD 구현
```cpp void Driver::submitIO(BIL::BIO &bio) { uint32_t cmd[16]; PRP *prp = nullptr; static ResponseHandler callback = this { _io(status, context); };
memset(cmd, 0, 64);
uint64_t slba = bio.offset / LBAsize; uint32_t nlb = (uint32_t)DIVCEIL(bio.length, LBAsize);
cmd[1] = namespaceID; // NSID
if (bio.type == BIL::BIO_READ) { cmd[0] = SimpleSSD::HIL::NVMe::OPCODE_READ; // CID, FUSE, OPC cmd[10] = (uint32_t)slba; cmd[11] = slba » 32; cmd[12] = nlb - 1; // LR, FUA, PRINFO, NLB
prp = new PRP(bio.length);
prp->getPointer(*(uint64_t *)(cmd + 6), *(uint64_t *)(cmd + 8)); // DPTR } else if (bio.type == BIL::BIO_WRITE) {
cmd[0] = SimpleSSD::HIL::NVMe::OPCODE_WRITE; // CID, FUSE, OPC
cmd[10] = (uint32_t)slba;
cmd[11] = slba >> 32;
cmd[12] = nlb - 1; // LR, FUA, PRINFO, DTYPE, NLB
prp = new PRP(bio.length);
prp->getPointer(*(uint64_t *)(cmd + 6), *(uint64_t *)(cmd + 8)); // DPTR } else if (bio.type == BIL::BIO_FLUSH) {
cmd[0] = SimpleSSD::HIL::NVMe::OPCODE_FLUSH; // CID, FUSE, OPC } else if (bio.type == BIL::BIO_TRIM) {
cmd[0] = SimpleSSD::HIL::NVMe::OPCODE_DATASET_MANAGEMEMT; // CID, FUSE, OPC
cmd[10] = 0; // NR
cmd[11] = 0x04; // AD
prp = new PRP(16);
prp->getPointer(*(uint64_t *)(cmd + 6), *(uint64_t *)(cmd + 8)); // DPTR
// Fill range definition
uint8_t data[16];
memset(data, 0, 16);
memcpy(data + 4, &nlb, 4);
memcpy(data + 8, &slba, 8);
prp->writeData(0, 16, data); }
submitCommand(1, (uint8_t *)cmd, callback, new IOWrapper(bio.id, prp, bio.callback)); }
###### nvme(driver) 구현
```c
blk_status_t nvme_setup_cmd(struct nvme_ns *ns, struct request *req,
struct nvme_command *cmd)
{
blk_status_t ret = BLK_STS_OK;
nvme_clear_nvme_request(req);
memset(cmd, 0, sizeof(*cmd));
switch (req_op(req)) {
case REQ_OP_DRV_IN:
case REQ_OP_DRV_OUT:
memcpy(cmd, nvme_req(req)->cmd, sizeof(*cmd));
break;
case REQ_OP_FLUSH:
nvme_setup_flush(ns, cmd);
break;
case REQ_OP_WRITE_ZEROES:
ret = nvme_setup_write_zeroes(ns, req, cmd);
break;
case REQ_OP_DISCARD:
ret = nvme_setup_discard(ns, req, cmd);
break;
case REQ_OP_READ:
case REQ_OP_WRITE:
ret = nvme_setup_rw(ns, req, cmd);
break;
default:
WARN_ON_ONCE(1);
return BLK_STS_IOERR;
}
cmd->common.command_id = req->tag;
trace_nvme_setup_cmd(req, cmd);
return ret;
}
submit command
- nvme에서는
struct blk_mq_hw_ctx *hctx를 parameter로 넣어주므로써 자연스럽게 nvme queue를 admin queue와 submission queue를 처리하는데, SimpleSSD 의 경우에는uint16_t iv라는 값을 전달하므로써 이를 처리한다. - 궁금점은 nvme에서는 spin_lock 을 걸어서 복사하는 과정에서 또다른 bio가 오는 것을 생각하고 있는 듯한 구현인데, SimpleSSD 의 경우에는 따로 lock을 거는 게 없다. 단일 쓰레드에서만 도는 걸 생각하는건가? 여기는 잘 모르겠다.
SimpleSSD 구현
```cpp void Driver::submitCommand(uint16_t iv, uint8_t *cmd, ResponseHandler &func, void *context) { uint16_t cid = 0; uint16_t opcode = cmd[0]; uint16_t tail = 0; uint64_t tick = engine.getCurrentTick(); Queue *queue = nullptr;
// Push to queue if (iv == 0) { increaseCommandID(adminCommandID); cid = adminCommandID; queue = adminSQ; } else if (iv == 1 && ioSQ) { increaseCommandID(ioCommandID); cid = ioCommandID; queue = ioSQ; } else { SimpleSSD::panic(“I/O Submission Queue is not initialized”); }
memcpy(cmd + 2, &cid, 2); queue->setData(cmd, 64); tail = queue->getTail();
// Push to pending cmd list pendingCommandList.push_back(CommandEntry(iv, opcode, cid, context, func));
// Ring doorbell pController->ringSQTailDoorbell(iv, tail, tick); queue->incrHead(); }
##### nvme구현
```c
/**
* nvme_submit_cmd() - Copy a command into a queue and ring the doorbell
* @nvmeq: The queue to use
* @cmd: The command to send
* @write_sq: whether to write to the SQ doorbell
*/
static void nvme_submit_cmd(struct nvme_queue *nvmeq, struct nvme_command *cmd,
bool write_sq)
{
spin_lock(&nvmeq->sq_lock);
memcpy(nvmeq->sq_cmds + (nvmeq->sq_tail << nvmeq->sqes),
cmd, sizeof(*cmd));
if (++nvmeq->sq_tail == nvmeq->q_depth)
nvmeq->sq_tail = 0;
if (write_sq)
nvme_write_sq_db(nvmeq);
spin_unlock(&nvmeq->sq_lock);
}
Work
SimpleSSD
- simplessd에선
Driver::submitCommand()에서pendingCommandList에CommandEntry를 넣은 뒤,pController->ringSQTailDoorbell를 해주는데, 이를 따라가보면, 인자로 넣어준 SQ의 tail을 이동시키는게 전부다…? - 여기서부터 순간 방향성을 잃었는데, SQ 넣고 어떻게 되지? 싶었다. 한번 SQ에 엑세스 하는걸 봐보자
- 그러면
Controller::work()가 나오게 된다. 이 함수는workEvent라는 변수에 담겨서Controller::writeRegister()에서 schedule에 등록된다. 이는Driver::init()에서 Step 5. 에서 일어난다. - 따라서 SimpleSSD 는
workInterval(기본값 : 50000, 50ns) 마다 SQ를 검사해서 처리하는 방식이다.nvme(driver)
nvme_write_sq_db()를 호출하는데, 이는 결국writel()를 호출해서 SQ tail 주소에 command를 쓰는 구조이다.-
그렇다면 nvme에서 command는 어떻게 되는가? : TODO: 흠…. 아직 잘 모르겠는데?
nvme_scan_work()가 있긴한데, 이게 user 가 scan work를 강제로 SSD에 시키는 건지가 모르겠는데, 근데 그런 구조면, 글러먹은게 IO 연산을 하기 위해서 직접 다 해줘야되는건데? 그러면 굳이 scheduler가 linux kernel level에 존재할 필요가 없는데? 그냥 scheduler layer 없이 SSD scan work 를 조절하면 되는데? 일단 추정은 ssd 내부에 존재하는건데, 이건 OpenChannelSSD 를 읽어보고 알아내야할듯. - 흐음…. 이건 잘 못찾았다. Controller 내부에 있다고 가정하고 계속 읽어 나가야할듯
SSD Interface
- HIL 의 SSD Interface는 단순한데
hil/hil.hh에SimpleSSD::HIL::HIL로 정의되어 있다. - I/O request를 host controller로 부터 받아
Interal Cache Layer에 넘겨준다.
Internal Cache Layer
- 여기서는 I/O buffer model (data cache)인 Internal Cache Layer (이하 ICL) 을 알아본다.
- ICL은 추상 클래스로 되어 있어서 상속 받아서 구현해볼수 있고 기본적으로는 set-associative cache 로 구현된 Generic Cache를 확인한다.
Abstract Class
icl/abstract_cache.hh에AbstractCache클래스로 선언되어 있으며 5가지 가상함수가 존재한다.(Statobject에서 파생된 3가지 함수들도 추가로 있다.)- ICL 은 각 가상함수로부터 I/O requests와 고유한 알고리즘에 의해서 bffer /IIO 를 가진다. data eviction이 필요하거나, flush request가 있을때 I/O를 FTL 에 넘긴다.
- SSD의 Data buffer는 느린 NAND I/O 성능을 감추기 위해서 매우 중요하다. buffer algorithm의 작은 변화도 성능을 크게 바꿀수 있다.
Set-Associative Cache
icl/generic_cache.hh에SimpleSSD::ICL::GenericCache라고 선언된 set-associative cache를 제공하며, 아래 후술될 인자를 조정할수 있다.CacheSize: Buffer Capacity.CacheWaySize: Set associativity of cache. set size will automatically caclculatedEnableReadCache: Enable read data caching.EnableReadPrefetch: enable read-ahead and prefetch.ReadPrefetchMode: Specify how many data should be read-ahead/prefetch.ReadPrefetchCount: Threshold for read-ahead/prefetch(# of sequential I/O).ReadPrefetchRatio: Threshold for read-ahead/prefetch(data size of sequential I/O).EnableWriteCache: enable write data caching.EvictPolicy: Specify which algorithm to use to select victim cache line.EvictMode: Specify how many data should be evicted when cache is full.CacheLatency: Set cache metadata accesss latency.
호출구조
hil/nvme/controller.cc에서Controller::work()를 확인해보면DMAContext를 만들어주고 호출하는 걸 알수 있다.- 여기서
checkQueue()를 호출하면서DMAFunction타입인func를 호출하게된다. 이때func은doQueue이고 이는 결국collectSQueue의 인자로 주어졌던CPUContext가 가지고 있는 함수를 호출한다. 이때 이건 결국handleRequest를 호출하게 된다. 이는SubSystem에 request를 전달하게 된다. -
결론은 결국 request는 처리되서 subsystem에 도달하게 되고, 이게 어떻게 처리되는지는
Subsystem::submitCommand()를 확인하면 알수 있다. 여기서 admin command 들을 처리하고, 아닌 것들은 그대로Namespace::submitCommand()로 넘어오게 된다. ```cpp void Namespace::submitCommand(SQEntryWrapper &req, RequestFunction &func) { /* Skip */ // NVM commands else { switch (req.entry.dword0.opcode) { case OPCODE_FLUSH: flush(req, func); break; case OPCODE_WRITE: write(req, func); break; case OPCODE_READ: read(req, func); break; case OPCODE_COMPARE: compare(req, func); break; case OPCODE_DATASET_MANAGEMEMT: datasetManagement(req, func); break; default: resp.makeStatus(true, false, TYPE_GENERIC_COMMAND_STATUS, STATUS_INVALID_OPCODE);response = true; break; } } }
if (response) { func(resp); } }
* 이때 `read` 함수등 은 다시 `Subsystem::read()`를 호출하고 이 내부는
```cpp
void Subsystem::read(Namespace *ns, uint64_t slba, uint64_t nlblk,
DMAFunction &func, void *context) {
Request *req = new Request(func, context);
DMAFunction doRead = [this](uint64_t, void *context) {
auto req = (Request *)context;
pHIL->read(*req);
delete req;
};
convertUnit(ns, slba, nlblk, *req);
execute(CPU::NVME__SUBSYSTEM, CPU::CONVERT_UNIT, doRead, req);
}
HIL::read()를 부르게 된다. 이렇게 불리게 된HIL::read()의 내부에서ICL::read()를 부르는 구조이다.- read 부분만 봤는데, 다른 부분도 비슷할거라고 생각한다.
Cache 로직 공부
- 결국
GenericCache::read()(읽기의 경우) 가 호출되게 되는데 그 과정을 적어보자 ```cpp /* return 값이 true 면 hit, 아니면 miss 이다. */ bool GenericCache::read(Request &req, uint64_t &tick) { bool ret = false;
debugprint(LOG_ICL_GENERIC_CACHE, “READ | REQ %7u-%-4u | LCA %” PRIu64 “ | SIZE %” PRIu64, req.reqID, req.reqSubID, req.range.slpn, req.length);
if (useReadCaching) { /* 읽기용 Cache가 있는지를 확인한다. / / start logical page number ? 의 약자인듯 / uint32_t setIdx = calcSetIndex(req.range.slpn); / Set-Associative Cache 를 참조 */ uint32_t wayIdx; uint64_t arrived = tick;
/* 이건 먼지 모르겠다. 연속적인 request를 체크하는건가 ?
* 찾아보니 prefetch 와 관련된 건데, 언제나 predict 를 sequential 이라고 생각하고 하는건가?
* 물론 prefetch 할 영역을 고르는데 어려운 알고리즘을 쓰면 문제가 많겠지만 Sequential 만 prefetch 하는게
* 좋다라는 논문이 있나?
* TODO: 논문 리딩
*/
if (useReadPrefetch) {
checkSequential(req, readDetect);
}
wayIdx = getValidWay(req.range.slpn, tick);
// Do we have valid data?
if (wayIdx != waySize) {
uint64_t tickBackup = tick;
// Wait cache to be valid
if (tick < cacheData[setIdx][wayIdx].insertedAt) {
tick = cacheData[setIdx][wayIdx].insertedAt;
}
// Update last accessed time
cacheData[setIdx][wayIdx].lastAccessed = tick;
// DRAM access
pDRAM->read(&cacheData[setIdx][wayIdx], req.length, tick);
debugprint(LOG_ICL_GENERIC_CACHE,
"READ | Cache hit at (%u, %u) | %" PRIu64 " - %" PRIu64
" (%" PRIu64 ")",
setIdx, wayIdx, arrived, tick, tick - arrived);
ret = true;
// Do we need to prefetch data?
if (useReadPrefetch && req.range.slpn == prefetchTrigger) {
debugprint(LOG_ICL_GENERIC_CACHE, "READ | Prefetch triggered");
req.range.slpn = lastPrefetched;
// Backup tick
arrived = tick;
tick = tickBackup;
goto ICL_GENERIC_CACHE_READ;
}
}
// We should read data from NVM
else {
ICL_GENERIC_CACHE_READ:
FTL::Request reqInternal(lineCountInSuperPage, req);
std::vector<std::pair<uint64_t, uint64_t>> readList;
uint32_t row, col; // Variable for I/O position (IOFlag)
uint64_t dramAt;
uint64_t beginLCA, endLCA;
uint64_t beginAt, finishedAt = tick;
if (readDetect.enabled) {
// TEMP: Disable DRAM calculation for prevent conflict
pDRAM->setScheduling(false);
if (!ret) {
debugprint(LOG_ICL_GENERIC_CACHE, "READ | Read ahead triggered");
}
beginLCA = req.range.slpn;
// If super-page is disabled, just read all pages from all planes
if (prefetchMode == MODE_ALL || !bSuperPage) {
endLCA = beginLCA + lineCountInMaxIO;
prefetchTrigger = beginLCA + lineCountInMaxIO / 2;
}
else {
endLCA = beginLCA + lineCountInSuperPage;
prefetchTrigger = beginLCA + lineCountInSuperPage / 2;
}
lastPrefetched = endLCA;
}
else {
beginLCA = req.range.slpn;
endLCA = beginLCA + 1;
}
for (uint64_t lca = beginLCA; lca < endLCA; lca++) {
beginAt = tick;
// Check cache
if (getValidWay(lca, beginAt) != waySize) {
continue;
}
// Find way to write data read from NVM
setIdx = calcSetIndex(lca);
wayIdx = getEmptyWay(setIdx, beginAt);
if (wayIdx == waySize) {
wayIdx = evictFunction(setIdx, beginAt);
if (cacheData[setIdx][wayIdx].dirty) {
// We need to evict data before write
calcIOPosition(cacheData[setIdx][wayIdx].tag, row, col);
evictData[row][col] = cacheData[setIdx] + wayIdx;
}
}
cacheData[setIdx][wayIdx].insertedAt = beginAt;
cacheData[setIdx][wayIdx].lastAccessed = beginAt;
cacheData[setIdx][wayIdx].valid = true;
cacheData[setIdx][wayIdx].dirty = false;
readList.push_back({lca, ((uint64_t)setIdx << 32) | wayIdx});
finishedAt = MAX(finishedAt, beginAt);
}
tick = finishedAt;
evictCache(tick);
for (auto &iter : readList) {
Line *pLine = &cacheData[iter.second >> 32][iter.second & 0xFFFFFFFF];
// Read data
reqInternal.lpn = iter.first / lineCountInSuperPage;
reqInternal.ioFlag.reset();
reqInternal.ioFlag.set(iter.first % lineCountInSuperPage);
beginAt = tick; // Ignore cache metadata access
// If superPageSizeData is true, read first LPN only
pFTL->read(reqInternal, beginAt);
// DRAM delay
dramAt = pLine->insertedAt;
pDRAM->write(pLine, lineSize, dramAt);
// Set cache data
beginAt = MAX(beginAt, dramAt);
pLine->insertedAt = beginAt;
pLine->lastAccessed = beginAt;
pLine->tag = iter.first;
if (pLine->tag == req.range.slpn) {
finishedAt = beginAt;
}
debugprint(LOG_ICL_GENERIC_CACHE,
"READ | Cache miss at (%u, %u) | %" PRIu64 " - %" PRIu64
" (%" PRIu64 ")",
iter.second >> 32, iter.second & 0xFFFFFFFF, tick, beginAt,
beginAt - tick);
}
tick = finishedAt;
if (readDetect.enabled) {
if (ret) {
// This request was prefetch
debugprint(LOG_ICL_GENERIC_CACHE, "READ | Prefetch done");
// Restore tick
tick = arrived;
}
else {
debugprint(LOG_ICL_GENERIC_CACHE, "READ | Read ahead done");
}
// TEMP: Restore
pDRAM->setScheduling(true);
}
}
tick += applyLatency(CPU::ICL__GENERIC_CACHE, CPU::READ); } else {
FTL::Request reqInternal(lineCountInSuperPage, req);
pDRAM->write(nullptr, req.length, tick);
pFTL->read(reqInternal, tick); }
stat.request[0]++;
if (ret) { stat.cache[0]++; }
return ret; }
```