mysql (storage engine)
created : 2020-05-27T22:48:47+00:00
modified : 2022-03-25T18:44:02+00:00
참고용 홈페이지
- https://dev.mysql.com/doc/internals/en/custom-engine.html
- mysql architecture
- https://dev.mysql.com/doc/dev/mysql-server/latest/PAGE_PFS_PSI.html
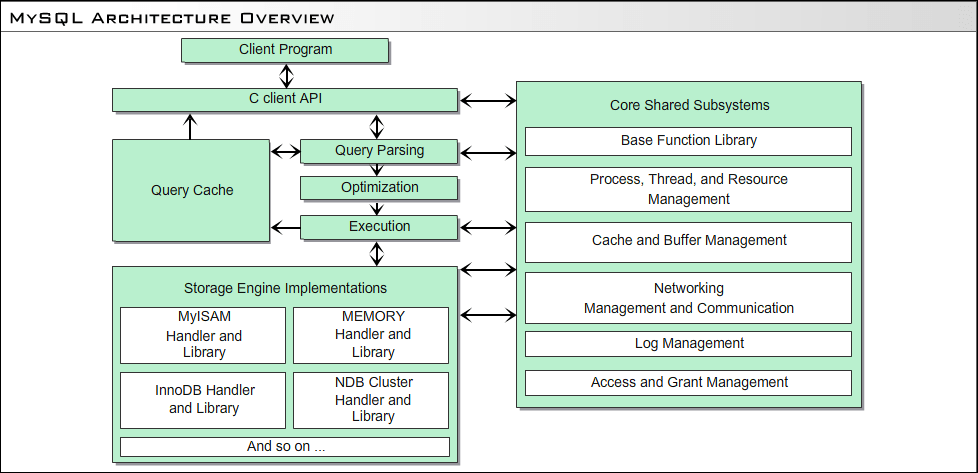
환경 설정
- 일단 지금 집에다가 예전에 썻던 삼성 노트북을 wol 으로 설정하고 (완전히 꺼지면 안켜지니까 shutdown 을 alias 해놓고, suspend를 사용하는 식으로 했다.휴가 때 마다 혹은 가끔씩 reboot 해주면 되겠지?)
- github 에서 다운로드 해서 private repository 에다가 올려놨다.
$ git clone https://github.com/mysql/mysql-server - 참고용 홈페이지 1을 보면 알 수 있듯이
storage/example을 똑같이 카피했다. - 일단 지금 목표는 custom engine 을 만들어 보는 거고 가능하다면 2018년 FAST 에 나온 논문인 FAST_PAIR 를 만들어보는거다.
- 일단 공부한 내용을 아래에 써놓겠다.
겪었던 문제들
- git push 를 할때 너무 많아서 그런지 안올라가진다. -> 브랜치를 나눠서 올리면 된다. mysql 8.0.0 까진 수월하게 올라간다. mysql-8.0.0 브랜치까지 올리고 나머지 올리면 올라가진다. 용량이 커서 안올라가지는 것 같다.
코딩할 때 알아야할 내용
mysys.h 관련
include/mysys.h에 사용할만한 함수들이 많이 정리되어 있다.- File 관련 :
my_create,my_close - 문자열 관련 :
fn_format(filename format) -to(buffer variable),name,dir,extension,flags순서 - Memory 관련 :
my_malloc,my_freeTHD (mysql thread 객체) 관련
- mysql thread 객체 (
THD) 에 변수로 넣으면 (THDVAR_SET) 복사가 일어난다. (추측) -> 따라서 넣어야할 값이 있으면 my_malloc 하고 넣은다음에 my_free 해줘야한다. (Memory Leak 나지 않게 조심하자!) - Mysql Thread 객체 (THD)에 값 확인, 넣기 :
THDVAR(대상 Thread, 원하는 변수명),THDVAR_SET(대상 Thread, 원하는 변수명, 값의 주소)
Debug
- Debug를 위해서 return 같은거 할때
DBUG_RETURN을 적극적으로 활용하자
참고용 홈페이지 읽고 정리하기
23.2 Overview
handler라는 interface를 구현하도록 되어 있는데, 각 connection 마다 thread가 생성되고 각 thread마다 handler instance를 생성하고 가지고 있도록 한다.- 질문점 : 그러면 각 handler들이 같은 table에 접근하게 되면 어떻게 되나 : handler를 구현할때 알아서 해결해야 한다. 가장 단순한 해결법은 table마다 lock을 가지게 해서 동시에 handler들이 접근 못하도록 하는것. (생각해보면 read lock, write lock마다 구현법도 다양하고 mvcc같은거 고려하면 생각할게 너무 많을 텐데 당연하게도 storage engine이 알아서 처리하도록 하는게 맞다)
- read-only -> insert, update, delete -> indexing, transactions -> other advanced options 순서로 구현하라고 한다.
23.3 Creating Storage Engine Source Files
example을 복사해서 수정하는게 제일 단순하다 (사실 이렇게 공식 홈페이지 적어놓을만 한게, innobase(=innodb)코드를 보고 비슷하게 만들어보려고 시도했는데, 나에게는 이건 너무 어려웠다. ㅠ)23.4 Adding Engine Specific Variables and Parameters
- 구조가 Plugin 식으로 추가되는 식인것 같은데 그래서 Plugin 을 만드는 방법에 대해서 나와있다.
- 이걸 열심히 공부하는것도 맞지만, 조금 목표와 멀어질 것 같아서 일단은 innobase 꺼 CMakeLists.txt 를 참고했고, 나중에 필요하면 다시 보면 될거라고 생각한다.
23.5 Creating the handlerton
handlerton(= handler singleton) : storage engine 마다 1개씩 있는 객체로, transaction을 다루는 commit, rollbacks 같은 기능을 제공하게 된다.typedef struct { const char *name; /* storage engine 의 이름 : CREATE TABLE ... ENGINE=FOO; 에 쓰인다. */ SHOW_COMP_OPTION state; /* SHOW STORAGE ENGINES command를 사용하면 출력되는 값 */ const char *comment; /* SHOW STORAGE ENGINES command를 사용할때 출력되는 설명 */ enum db_type db_type; /* custom engine 은 반드시 DB_TYPE_UNKNOWN 을 사용해야한다고 합니다. */ bool (*init)(); /* Server 가 시작할때 딱 1번 불리게 되고, handler가 instance 화 되기 전에 처리되야할 내용을 넣으면된다. */ uint slot; /* storage engine 마다 고유하게 가지고있는 메모리 영역 thd->ha_data[foo_hton.slot]으로 접근가능하고, Rollback 구현할떄 참조하라고 적혀있음 */ uint savepoint_offset; /* savepoint 의 위치, 0이면 savepoint memory가 필요하지 않다. */ int (*close_connection)(THD *thd); int (*savepoint_set)(THD *thd, void *sv); int (*savepoint_rollback)(THD *thd, void *sv); int (*savepoint_release)(THD *thd, void *sv); int (*commit)(THD *thd, bool all); int (*rollback)(THD *thd, bool all); int (*prepare)(THD *thd, bool all); int (*recover)(XID *xid_list, uint len); int (*commit_by_xid)(XID *xid); int (*rollback_by_xid)(XID *xid); void *(*create_cursor_read_view)(); void (*set_cursor_read_view)(void *); void (*close_cursor_read_view)(void *); handler *(*create)(TABLE *table); void (*drop_database)(char* path); int (*panic)(enum ha_panic_function flag); int (*release_temporary_latches)(THD *thd); int (*update_statistics)(); int (*start_consistent_snapshot)(THD *thd); bool (*flush_logs)(); bool (*show_status)(THD *thd, stat_print_fn *print, enum ha_stat_type stat); int (*repl_report_sent_binlog)(THD *thd, char *log_file_name, my_off_t end_offset); uint32 flags; } handlerton;- 적다보니 아래 부분은 transcation 을 구현할때나 필요한 부분이라 나중에 생각하기로 했다. 대충 공식 메뉴얼정도만 읽었고 굳이 번역해놓을 필요는 없을듯?
23.6 Handling Handler Instantiation
static handler* example_create_handler (TABLE* table);
- handler 생성 함수를 만들어야된다.
- handler constructor를 단순히 호출하는 형식으로 구현할 수도 있다. (아래 예시는 myisam 의 구현)
static handler *myisam_create_handler(TABLE *table)
{
return new ha_myisam(table);
}
- constructor 의 구현 예시
ha_federated::ha_federated(TABLE *table_arg)
:handler(&federated_hton, table_arg),
mysql(0), stored_result(0), scan_flag(0),
ref_length(sizeof(MYSQL_ROW_OFFSET)), current_position(0)
{}
23.7 Defining Filename Extensions
- 지원하는 확장자를
const char* []로 넘기면 처리해준다 - 단 array 의 마지막 은
NullS로 끝나야함. - 아래 코드는 csv 예시
static const char *ha_tina_exts[] = {
".CSV",
NullS
};
- 이렇게 정의된 array를 다음과 같이 설정해주면 됨.
const char **ha_tina::bas_ext() const
{
return ha_tina_exts;
}
DROP TABLE에서 table을 지웠을 때 파일이 삭제되는 기능을 딱히 구현하지 않고 생략해도 된다.- 근데 이건 필수가 아닌 건지,
handlerclass에 따로 선언되어 있지는 않다. -> 직접 구현했는데 혹시 문제가 생길수도 있으니 메모해놓는다.
23.8 Creating Tables
virtual int create(const char *name, TABLE *form, HA_CREATE_INFO *info)=0;
- 위 함수를 반드시 구현하라고 한다.
name은table의 이름form은tablename이랑 매칭되는TABLEstructure :tablename.frm이라는 파일에 이미 다 만들어 놨으니, Storage Engine은 이를 변경하면 안됨.info는CREATE TABLE을 했을 때 생기는 정보.handler.h에 정의 되어 있으니 참조.
typedef struct st_ha_create_information
{
CHARSET_INFO *table_charset, *default_table_charset;
LEX_STRING connect_string;
const char *comment,*password;
const char *data_file_name, *index_file_name;
const char *alias;
ulonglong max_rows,min_rows;
ulonglong auto_increment_value;
ulong table_options;
ulong avg_row_length;
ulong raid_chunksize;
ulong used_fields;
SQL_LIST merge_list;
enum db_type db_type;
enum row_type row_type;
uint null_bits; /* NULL bits at start of record */
uint options; /* OR of HA_CREATE_ options */
uint raid_type,raid_chunks;
uint merge_insert_method;
uint extra_size; /* length of extra data segment */
bool table_existed; /* 1 in create if table existed */
bool frm_only; /* 1 if no ha_create_table() */
bool varchar; /* 1 if table has a VARCHAR */
} HA_CREATE_INFO;
- storage engine 이 파일 기반이라는 가정하에
form,info는 신경 쓰지 않아도 됨. - csv engine 같은 경우 아래와 같이 구현되어 있음
int ha_tina::create(const char *name, TABLE *table_arg,
HA_CREATE_INFO *create_info)
{
char name_buff[FN_REFLEN];
File create_file;
DBUG_ENTER("ha_tina::create");
if ((create_file= my_create(fn_format(name_buff, name, "", ".CSV",
MY_REPLACE_EXT|MY_UNPACK_FILENAME),0,
O_RDWR | O_TRUNC,MYF(MY_WME))) < 0)
DBUG_RETURN(-1);
my_close(create_file,MYF(0));
DBUG_RETURN(0);
}
- 흐음…. 딱히 예제 코드에서 수정할게 없어보여서 거의 그대로 가져왔다.
- 변경한 부분은 확장자 부분이랑, ccls에서 warning을 뱉길레 if문 안에 assignment구문을 넣지 않고 밖으로 뺴기만 했다.
- 그리고 원래 example source에 thread variable 을 설정하는 예시로 현재 사용하고 있는 Thread(아마도 내 추측으로는 client의 connection과 동일한 맥락을 가질듯, server에서는 connection 당 1개의 thread가 붙어서 담당한다고 알고 있음, 이건 위에 Overview 참고)마다 생성시킨 Table 개수를 tracking 하는 코드가 있었는데, 굳이 문제가 안될것 같아서 냅뒀다.
23.9 Opening a Table
- read나 write 연산 전에 반드시 table data와 index file(있다면)을 열도록 되어있다.
int open(const char *name, int mode, int test_if_locked);
name은 table 의 이름mode는O_RDONLY(Open read only) 또는O_RDWR(Open read/write)test_if_locked는 파일을 열 때 확인해야할 내용에 대한 값이고,
#define HA_OPEN_ABORT_IF_LOCKED 0 /* default */
#define HA_OPEN_WAIT_IF_LOCKED 1
#define HA_OPEN_IGNORE_IF_LOCKED 2
#define HA_OPEN_TMP_TABLE 4 /* Table is a temp table */
#define HA_OPEN_DELAY_KEY_WRITE 8 /* Don't update index */
#define HA_OPEN_ABORT_IF_CRASHED 16
#define HA_OPEN_FOR_REPAIR 32 /* open even if crashed */
- 이 값들중 하나이다.
- lock을 어떻게 다루는지 같은건
get_share()와free_share()를 참조하라고 한다.
코드 보면서 느낀거
handler::ha_open이라는 메서드가 존재하는데 얘가handler::open을 호출하는 구조이다. (정확히 여기서는handler를 상속받은 custom storage engine의 open이라는 메서드)- csv 의
ha_tina를 보면 (물론 여기서는 싱글톤? share를 활용해서 파일을 여는 구조인것 같다.)mysql_file_open이라는 메서드를 사용해서 처리하는데, 여기서 받는 첫번째 인자가PSI_file_key인데 이게 먼지 모르겠다. 참조 3에 있는 홈페이지에서 검색해서 찾아보면, 계측된? (instrumented) 파일 이라고 하는데…. 아예 innobase에서는mysql_file_open이라는 걸 사용하지도 않는다. csv에서도 static하게 선언해놓고 그냥 사용한다. 자동으로 채워지는 데이터 구조인지 잘모르겠다. -
흐음… 찾아보았는데 file을 생성할 때 PSI_file_key를 같이 주고서 생성하면 넣어주는 방식인듯. 내가 구현할 때는
my_create를 사용해서 생성했으니까, 그냥my_open으로 파일을 열어서 사용하면 될 듯. 사용하는 곳들을 보니까 전부 singleton 이거나 metadata 임. - dictionary file 은 singleton (
handlerton) 에서 vector 의 형식으로 관리하고, data file 은 handler 들이 각자 가지도록 구현해놔야할듯. open 이라는 메서드 자체가 테이블을 열어야할 필요가 있을 때만 열린다고 하니까 dictionary 가 안열릴 수 도 있다는 가정 하에 코딩해야된다. - handlerton 의 lifecycle 을 확인해서 handlerton 이 죽을 때(아마도 예측은 mysql server 가 죽을 때) 들고 있는 dictionary file을 해제하는 형식으로 해줘야 할듯.
- 일단 indirect data 구조로 짜서 dictionary 에는 data file 의 page number 와 page 의 offset을 들고 있도록 구현하자…. 흐음… 이렇게 짜면 innodb랑 엄청 비슷한거 같은데? 흥… 근데 이것 보다 좋은 방식이 따로 떠오르지는 않는데? 일단 생각한대로 해보자.(innodb 보다 성능이 잘나올지는 모르겠다. 흐음…)
23.10 Implementing Basic Table Scanning
23.10.1 Implementing the store_lock() Method
- reading이나 writing 이 발생하기 전에 언제나 불림
- table에 lock을 추가하기 전에
mysqld라는 lock handler가 요청된 locks을 store_lock을 호출한다. 이때 store lock은 lock 의 수준을 변경할수 있고(blocking을 non-blocking을 만들다던가, 아예 무시하도록 만들다던가) 아니면 다른 테이블들에 락을 추가할수도 있다. -
lock을 풀어줄때 store_lock이 다시 불리게 되는데, 이런 경우에는 일반적으로는 아무것도 할 필요가 없다.
- 만약 store_lock에 TL_IGNORE가 파라메터로 들어온다면, mysql에 handler에게 마지막에 요청했던 락을 다시 요청하는 것과 같다.
- lock의 종류는
includes/thr_lock.h에 기재되어 있고 밑에 나와있는 것과 동일하다.
enum thr_lock_type
{
TL_IGNORE=-1,
TL_UNLOCK, /* UNLOCK ANY LOCK */
TL_READ, /* Read lock */
TL_READ_WITH_SHARED_LOCKS,
TL_READ_HIGH_PRIORITY, /* High prior. than TL_WRITE. Allow concurrent insert */
TL_READ_NO_INSERT, /* READ, Don't allow concurrent insert */
TL_WRITE_ALLOW_WRITE, /* Write lock, but allow other threads to read / write. */
TL_WRITE_ALLOW_READ, /* Write lock, but allow other threads to read / write. */
TL_WRITE_CONCURRENT_INSERT, /* WRITE lock used by concurrent insert. */
TL_WRITE_DELAYED, /* Write used by INSERT DELAYED. Allows READ locks */
TL_WRITE_LOW_PRIORITY, /* WRITE lock that has lower priority than TL_READ */
TL_WRITE, /* Normal WRITE lock */
TL_WRITE_ONLY /* Abort new lock request with an error */
};
ha_myisammrg::store_lock()을 참조
23.10.2 Implementing the external_lock() Method
- statement 의 시작이나,
LOCK TABLES라는 게 들어오면external_lock()이 호출된다. external_lock()은 ha_innodb.cc에서 찾아보면 된다. 대부분의 storage engine이 간단하게 return 0 하는 식으로 구현한다.
23.10.3 Implementing the rnd_init() Method
rnd_init()은 table scan 을 준비하는 단계에서 호출되고, counters를 초기화 시키거나, pointers를 table의 시작지점에 만든다.- 간단한 CSV storage engine의 구현 예시이다.
int ha_tina::rnd_init(bool scan)
{
DBUG_ENTER("ha_tina::rnd_init");
current_position= next_position= 0;
records= 0;
chain_ptr= chain;
DBUG_RETURN(0);
}
- 만약 sequential read면
scan은true, random read 면false이다.
23.10.4 Implementing the info(uinf flag) Method
- table scan을 하기 전에 optimizer에게 추가적인 테이블 정보를 넘겨주기 위해서 불린다.
- return 값으로 정보를 전달하는 식이아니라 handler class의 몇몇 맴버 변수를 통해서 가져간다.
- optimizer가 사용하는 것 이외에도
SHOW TABLE STATUS에서도 내용을 보게 된다. 이때flag인자는 어떠한 맥락에서 이 메서드가 호출되었는지를 전달해준다.HA_STATUS_NO_LOCK: table shared의 lock을 방지할수 있다면, handler가 오래된걸 사용한다. (직역해서 좀 이상한데, lock 없이 가능하다면 오래된 버전을 본다. 아 풀어서 써도 이상하네… mvcc 같은 개념을 생각하면 될듯)HA_STATUS_TIME: 오직stats->update_time만 필요하다. (나머진 업데이터 안해도 된다.)HA_STATUS_CONST: immutable member를 업데이트 해라 (max-data_file_length,max_index_file_length,create_time,sortkey,ref_length,block_size,data_file_name,index_file_name)HA_STATUS_VARIABLE:records,deleted,data_file_length,index_file_length,delete_length,check_time,mean_rec_lengthHA_STATUS_ERRKEY: 마지막으로 발생한 error keyHASTATUS_AUTO: autoincrement value 를 업데이트 해라.
- 아래는
sql/handler.h에 정의되어 있는 public properties
ulonglong data_file_length; /* Length off data file */
ulonglong max_data_file_length; /* Length off data file */
ulonglong index_file_length;
ulonglong max_index_file_length;
ulonglong delete_length; /* Free bytes */
ulonglong auto_increment_value;
ha_rows records; /* Records in table */
ha_rows deleted; /* Deleted records */
ulong raid_chunksize;
ulong mean_rec_length; /* physical reclength */
time_t create_time; /* When table was created */
time_t check_time;
time_t update_time;
-
table scan의 목적에선, 가장 중요한 property는 records (table의 records 개수) 이다. 0, 1, 2보다 많음에 대한 정보가 중요하게 쓰인다. 2보다 많으면 더 많은건 따로 신경 안써도 된다.
-
아래는
ha_tina의 예제이다.int ha_tina::info(uint flag) { DBUG_ENTER("ha_tina::info"); /* This is a lie, but you don't want the optimizer to see zero or 1 */ if (!records_is_known && stats.records < 2) stats.records= 2; DBUG_RETURN(0); }
23.10.5 Implementing the extra() method
- 추가적인 hint 를 주기 위해서 호출되는 method
- extra call 을 구현하는건 의무가 아니여서 대부분 0을 리턴함
- 너무 설명이 없다. 어떤 상황에서 추가적인 hint가 필요한지, parameter 가 왜
int ha_tina::extra(enum ha_extra_function operation)이런식으로 구성되어 있는지에 대한 설명이 부족한듯.
- 너무 설명이 없다. 어떤 상황에서 추가적인 hint가 필요한지, parameter 가 왜
23.10.6 Implementing the rnd_next() method
- 각 row를 가져올때마다 호출되며, server의 search condition 이 만족되었거나 파일의 끝에 도달하면
HA_ERR_END_OF_FILE을 리턴해야한다. rnd_next()는 byte array 인buf를 인자로 받는다. 이때 buf 는 반드시 mysql 의 table row 의 포멧을 따라야한다.- 3가지 포멧을 지원하는데, fixed-length rows, variable-length rows, variable-length rows with BLOB pointers 이다.
- 모두
CREATE TABLE의 순서를 따라야한다. (table의 정의는.frm에 있으며, optimizer와 handler 에서 최적화 할 수 있다.) - 각 format 마다 nullable column 마다 1bit의 NULL bitmaps 으로 시작한다. (만약 8개의 Nullable Column 이 존재한다면, 1byte 의 bitmap 이 존재할거다.)
- 딱 하나 예외가 있는데, fixed-width table인데, 이때는 추가 시작 bit가 있으므로 8개의 Nullable columns 을 가지고 있는 table은 2bytes bitmap 이 존재한다.
- Nullbitmap 구역이 끝나면, Columns의 datatypes가 있다. datatype 에 대한 정의는
sql/field.cc에 정의 되어 있다. - fixed length row format 에서는 간단하게 하나 다음 하나 형식으로 존재한다. variable length row에서는 VARCHAR는 1이나 2 bytes 길이로 부호화 되어 있다.
- BLOB을 포함하는 variable length row 에서는 각 BLOB은 2부분으로 저장되는 데, 1번째는 BLOB의 크기를 저장하는 integer, 2번째는 BLOB의 내용에 대한 pointer 이다.
- 다음은 csv 의 예시이다.
int ha_tina::rnd_next(byte *buf)
{
DBUG_ENTER("ha_tina::rnd_next");
statistic_increment(table->in_use->status_var.ha_read_rnd_next_count, &LOCK_status);
current_position= next_position;
if (!share->mapped_file)
DBUG_RETURN(HA_ERR_END_OF_FILE);
if (HA_ERR_END_OF_FILE == find_current_row(buf) )
DBUG_RETURN(HA_ERR_END_OF_FILE);
records++;
DBUG_RETURN(0);
}
int ha_tina::find_current_row(byte *buf)
{
byte *mapped_ptr= (byte *)share->mapped_file + current_position;
byte *end_ptr;
DBUG_ENTER("ha_tina::find_current_row");
/* EOF should be counted as new line */
if ((end_ptr= find_eoln(share->mapped_file, current_position,
share->file_stat.st_size)) == 0)
DBUG_RETURN(HA_ERR_END_OF_FILE);
for (Field **field=table->field ; *field ; field++)
{
buffer.length(0);
mapped_ptr++; // Increment past the first quote
for(;mapped_ptr != end_ptr; mapped_ptr++)
{
// Need to convert line feeds!
if (*mapped_ptr == '"' &&
(((mapped_ptr[1] == ',') && (mapped_ptr[2] == '"')) ||
(mapped_ptr == end_ptr -1 )))
{
mapped_ptr += Move past the , and the "
break;
}
if (*mapped_ptr == '\\' && mapped_ptr != (end_ptr - 1))
{
mapped_ptr++;
if (*mapped_ptr == 'r')
buffer.append('\r');
else if (*mapped_ptr == 'n' )
buffer.append('\n');
else if ((*mapped_ptr == '\\') || (*mapped_ptr == '"'))
buffer.append(*mapped_ptr);
else /* This could only happed with an externally created file */
{
buffer.append('\\');
buffer.append(*mapped_ptr);
}
}
else
buffer.append(*mapped_ptr);
}
(*field)->store(buffer.ptr(), buffer.length(), system_charset_info);
}
next_position= (end_ptr - share->mapped_file)+1;
/* Maybe use \N for null? */
memset(buf, 0, table->s->null_bytes); /* We do not implement nulls! */
DBUG_RETURN(0);
}
23.11 Closing a Table
- Table 에서 작업을 마치면 호출된다.
- shared resource를 반환해야 한다.
23.12 Adding Support for INSERT to a Storage Engine
- read를 다 구현하면 write를 구현해야하고, WORM(Write Once, Read Many) application을 다뤄야한다.
- 모든 INSERT 구문은
write_row()로 다룬다.
int ha_foo::write_row(byte *buf)
-
이때
buf는 mysql format을 따라서 전달한다. -
다음은
MyISAM의 예시이다.
int ha_myisam::write_row(byte * buf)
{
statistic_increment(table->in_use->status_var.ha_write_count,&LOCK_status);
/* If we have a timestamp column, update it to the current time */
if (table->timestamp_field_type & TIMESTAMP_AUTO_SET_ON_INSERT)
table->timestamp_field->set_time();
/*
If we have an auto_increment column and we are writing a changed row
or a new row, then update the auto_increment value in the record.
*/
if (table->next_number_field && buf == table->record[0])
update_auto_increment();
return mi_write(file,buf);
}
23.13 Adding Support for UPDATE to a Stroage Engine
- 먼저 (table/index/range/etc) scan 을 통해서 where 절에 해당하는 걸 찾고 update_row()를 호출한다.
int ha_foo::update_row(const byte *old_data, byte *new_data)
old_data는 update 되어야 되는 data를 가르키고 있고,new_data는 새롭게 들어갈 내용을 가지고 있다.- row format 에 따라 성능이 갈리며, 어떤 경우에는 기존 데이터를 지우고 맨 뒤에 새롭게 추가하는 식으로 구현한다.
- 아래는 csv 의 예시이다.
int ha_tina::update_row(const byte * old_data, byte * new_data)
{
int size;
DBUG_ENTER("ha_tina::update_row");
statistic_increment(table->in_use->status_var.ha_read_rnd_next_count,
&LOCK_status);
if (table->timestamp_field_type & TIMESTAMP_AUTO_SET_ON_UPDATE)
table->timestamp_field->set_time();
size= encode_quote(new_data);
if (chain_append())
DBUG_RETURN(-1);
if (my_write(share->data_file, buffer.ptr(), size, MYF(MY_WME | MY_NABP)))
DBUG_RETURN(-1);
DBUG_RETURN(0);
}
23.14 Adding Support for DELETE to a Storage Engine
- DELETE 도 UPDATE와 비슷하게 처리하며,
rnd_next()를 호출하다가delete_row()를 호출한다. buf는 삭제될 내용을 가리킨다. Non-indexed storage engine 은 무시할수도 있지만, transaction을 지원하는 storage engine 은 rollback 작업을 위해 삭제할 내용을 저장할 필요가 있다.- 아래는 csv의 구현 예시이다.
int ha_tina::delete_row(const byte * buf)
{
DBUG_ENTER("ha_tina::delete_row");
statistic_increment(table->in_use->status_var.ha_delete_count,
&LOCK_status);
if (chain_append())
DBUG_RETURN(-1);
--records;
DBUG_RETURN(0);
}
23.15 Supporting Non-Sequential Reads
23.15.1 Implementing the position() Method
rnd_next()가 불린뒤 데이터를 재정렬할 필요가 있을 때position()이 호출된다.
void ha_foo::position(const byte *record)
this->ref안에 record의 position 이 저장된다. 이때 position에 저장된 contents는 맘대로 해도 된다.- position 에 나중에 검색하기 위한 정보만 들어있으면 된다. 대부분의 Storage Engine은 primary key 의 offset을 가지고 있다.
23.15.2 Implementing the rns_pos() Method
rnd_next()와 비슷하게 구현하면 된다.
int ha_foo::rnd_pos(byte * buf, byte *pos)
pos에는position()method 를 사용해서 미리 기록된 정보를 포함하는 인자이다.buf는 mysql format 에 맞추어서 데이터를 넣어줘야 한다.
여담
- 흐음… Index 말고 non-sequential read? 이게 어쩔때 호출되는지 모르겠었다. -> 아 23.15 시작할때 적혀있었다.
multi-table UPDATE이나SELECT .. table.blob_column ORDER BY something일때 사용한다. 그러므로 선택사항이 아닌 필수 구현사항이다.
23.16 Supporting Indexing
23.16.1 Indexing Overview
- Indexing 을 지원하는 것은 2가지로 구성된다 : Optimizer 에게 정보를 제공하는 것과 그에 맞는 Method 구현이다.
- indexing method 는
- key에 맞는 row를 읽는 것
- index 순서에 맞춰서 a set of rows(데이터들)을 읽는 것
- index로부터 직접적으로 정보(information) 을 읽는 것.
- 중 하나이다.
UPDATE foo SET ts = now() WHERE id = 1:같은 Update query가 실행될때 다음과 같은 순서로 실행된다.
ha_foo::index_init
ha_foo::index_read
ha_foo::index_read_idx
ha_foo::rnd_next
ha_foo::update_row
- 추가적으로 index read를 지원한다면, storage engine 은 row가 추가, 제거, 수정 될 때에도 table index를 유지하기 위해서 새로운 index를 만드는 것을 지원해야 한다.
23.16.2 Getting Index Information During CREATE TABLE Operations
- 일반적으로 indexing read를 지원하는 storage engine 같은 경우,
CREATE TABLE할 때 index 정보를 제공한다. 나중에는 index 정보를 획득해서 만들기 어렵다. - TABLE 의
create()method 의 인자key_info는 다음과 같은 정보를 포함한다.
#define HA_NOSAME 1 /* Set if not duplicated records */
#define HA_PACK_KEY 2 /* Pack string key to previous key */
#define HA_AUTO_KEY 16
#define HA_BINARY_PACK_KEY 32 /* Packing of all keys to prev key */
#define HA_FULLTEXT 128 /* For full-text search */
#define HA_UNIQUE_CHECK 256 /* Check the key for uniqueness */
#define HA_SPATIAL 1024 /* For spatial search */
#define HA_NULL_ARE_EQUAL 2048 /* NULL in key are cmp as equal */
#define HA_GENERATED_KEY 8192 /* Automatically generated key */
flag외에도algorithm는 index type에 관련된 알고리즘 정보를 제공한다.enum ha_key_alg { HA_KEY_ALG_UNDEF= 0, /* Not specified (old file) */ HA_KEY_ALG_BTREE= 1, /* B-tree, default one */ HA_KEY_ALG_RTREE= 2, /* R-tree, for spatial searches */ HA_KEY_ALG_HASH= 3, /* HASH keys (HEAP tables) */ HA_KEY_ALG_FULLTEXT= 4 /* FULLTEXT (MyISAM tables) */ };flag와algorithm에외에도key_part라고 복합 키(composite key)의 개별적인 부분을 설명하는 array 가 있다.key_part는 key part와 연관된 field(압축되어야 하는지, index part 의 data type과 길이) 를 제공하고 자세한건ha_myisam.cc를 참조하면 어떻게 파싱해야할지 알 수 있다.- 추가적으로, storage engine 은 각 연산마다
handler의TABLE구조에서 index 를 읽을 수 있다.
23.16.3 Create Index Keys
INSERT,UPDATE,DELETE와 같이 테이블에 쓰기를 하는 연산시, Index 정보를 갱신해줘야한다.- index를 저장하는 방식이 다양하기 때문에, index를 갱신하는건 storage engine 마다 방법이 다양하다.
- 일반적으로는
write_row(),update_row(),delete_row()에서 넘어온 row 정보를 TABLE의 index 정보를 결합해서 활용한다.
23.16.4 Parsing Key Information
- 대부분의 index와 관련된 method 가 표준 규격의
key를 넘긴다. Storage Engine 을 구현할 때 필요한 정보를 추출해서 저장하고, 저장된 index정보를 가공해서 번역(translate)해야한다. - key 정보는 일정한 순서대로 되어 있는데,
table->key_info[index]->key_part[part_num]에 정의되어 있는 대로이다. - key와 함께 handler의 method는
keypart_map를 전달해서 key 인자에 존재하는 key의 부분을 나타낸다. keypart_map는ulonglong타입의 bitmap 이고, key part마다 비트가 켜져있다. (에시 : 1이 켜져있으면 keypart[0] 에 key가 존재한다. 2가 켜져있으면 keypart[1], 4가 켜져있으면 keypart[2])- 마지막 key part 뒤에 있는 bit는 중요하지 않으니 모든 keypart 마다 ~0 를 사용할수 있다. 현재는 prefix만 허용하니 다음과 같이 쓸수 있다.
assert((keypart_map + 1) & keypart_map == 0). keypart_map은records_in_range()에서 사용되는key_range의 일부분이므로,keypart_map은index_read(),index_read_idx()에서 인자로서 직접적으로 접근 할수 있다.- 옛날 handler 같은 경우
keypart_map대신key_len을 가지고 있다.key_len은 prefix 가 매칭될때 prefix 길이를 나타낸다.
23.16.5 Providing Index Information to the Optimizer
- Indexing 을 효과적으로 하기 위해서는 Optimizer(질의 최적화기?)에게 Index에 대한 정보를 제공해야한다. 이렇게 제공받은 정보로 Index를 사용할지, 쓴다면 어떤 Index를 사용할것인지를 결정한다.
23.16.5.1 Implementing the info() Method
handler:info()를 호출하면서 Optimizer는 정보를 얻는다. 이때info()는 return value로 정보를 제공하는게 아닌 handler의 public variable 을 설정하여서 필요할때 읽도록 한다.- 이런 값들은
INFORMATION SCHEMA에게SHOW TABLE STATUS같은 질의를 할때도 사용된다. - 가능하다면 모든 variable를 채우는게 좋지만, 만약 안된다고 해도 아래 서술하는 변수들은 반드시 채워야한다.
records- Table에 있는 row의 수, 만약 정확하게 산출하기 어렵다면, 1보다 큰 아무 값이라도 넣어놔야지 optimizer가 0개와 1개일때 최적화 하는 것을 방지할수 있다.deleted- Table에 들어있는 삭제된 row의 수. table fragmentation 여부를 판단할 때 사용한다.data_file_length- bytes 단위인 data 파일의 크기, optimizer 가 읽기 비용을 계산할때 사용한다.index_file_length- bytes 단위인 index파일의 크기, optimizer 가 읽기 비용을 계산할 때 사용한다.mean_rec_length- 1 row의 평균 크기, byte 단위scan_time- full scan 할때의 I/O 탐색의 비용delete_length- ??? 안적혀 있네check_time- 이것도 안적혀 있음.
- 비용을 계산할때 정확하게 계산하는 것보다는 빨리 나오는게 좋다. 어떻게 해야지 빠른지를 구하는데 오래걸린다면 의미가 없다.
- 대수를 추정하는 걸로 충분하다.
23.16.6.2 Implementing the records_in_range Method
- table 에 query 하거나 join할 때
records_in_range가 호출된다.
ha_rows ha_foo::records_in_range(uint inx, key_range *min_key, key_range *max_key)
inx는 확인되어야할 index,min_key와max_key는 범위의 양 끝값key_range는 다음과 같이 정의 되어있다.
typedef struct st_key_range
{
const byte *key;
uint length;
key_part_map keypart_map;
enum ha_rkey_function flag;
} key_range;
key- key buffer의 pointerlength- key의 길이keypart_map- 전달된key에서 key 부분이 어디인지를 가리키는 변수 : 자세한건 Parsing Key Information 참조flag- key가 범위에 포함되는지를 나타내는 변수min_key.flag는HA_READ_KEY_EXACT- 범위에 key가 포함됨HA_READ_AFTER_KEY- 범위에 key가 포함되지 않음
max_key.flag는HA_READ_BEFORE_KEY- 범위에 key가 포함되지 않음HA_READ_AFTER_KEY-end_key의 모든 값들이 범위에 포함됨.
- return value는 다음과 같다.
0- 주어진 범위에 key들이 있지 않음.number > 0- 주어진 범위에 대충number개 있음HA_POS_ERROR- index tree 조회하다 먼가 오류가 남.
- 속도가 정확도보다 중요함.
23.16.6 Preparing for Index Use with index_init()
- index를 사용하기 전 storage engine 이 사전작업이나 최적화를 할 수 있도록
index_init()을 호출해준다.
int ha_foo::index_init(uint keynr, bool sorted)
- 대부분의 storage engine 의 경우 딱히 사전작업을 할필요는 없다. 만약 명시적으로 따로 구현하지 않으면 아래의 함수를 사용하게 된다.
int handler::index_init(uint idx) { active_index=idx; return 0; }
23.16.7 Cleaning up with index_end()
index_init()과는 반대의 용도인데,index_init()에서 만든 것들을 없애는 목적이다.- 만약 따로
index_init()을 구현하지 않았다면,index_end()도 구현할 필요 없다.
23.16.8 Implementing the index_read() Method
- key를 기반으로 row를 찾기 위해서 사용된다.
int ha_foo::index_read(byte * buf, const byte * key,
ulonglong keypart_map,
enum ha_rkey_function find_flag)
buf는key에 해당하는 row를 넣을 byte arraykeypart_map은key에서 어느부분에 진짜 key가 저장되어 있는지를 나타내는 변수find_flag는 어떻게 동작할지를 나타내는 enumerator, 다음 값들을 가질 수 있다.
HA_READ_AFTER_KEY
HA_READ_BEFORE_KEY
HA_READ_KEY_EXACT
HA_READ_KEY_OR_NEXT
HA_READ_KEY_OR_PREV
HA_READ_PREFIX
HA_READ_PREFIX_LAST
HA_READ_PREFIX_LAST_OR_PREV
- storage engine은 key를 나름대로 (자기만의 형식으로 바꿔서)
find_flag에 해당하는 행의 row 값을buf에 mysql format으로 넣어야한다. - row를 찾아 반환한 이후에, storage engine은 sequential index read를 지원하도록 cursor를 설정해 둬야한다.
key가null일 경우 index의 첫번째 key를 읽어야한다. (흠?? key가 아니라 first key에 해당하는 row를 반환해야된다는 거겠지?)
23.16.8 Implementing the index_read_idx() Method
index_read_idx()는 추가적으로keynr이라는 인자를 받는 것을 빼고는index_read()와 동일하다.
int ha_foo::index_read_idx(byte * buf, uint keynr, const byte * key,
ulonglong keypart_map,
enum ha_rkey_function find_flag)
keynr인자는index_read에서는 기존에 설정된 index를 읽는 반면, 특정한 index를 읽도록 결정한다.index_read()와 마찬가지로 나중에 읽을수 있도록 cursor를 설정해 두어야한다.
23.16.10 Implementing the index_read_last() Method
index_read_last()도index_read()와 비슷하게 동작한다.- 하지만 주어진
key에 해당하는 맨마지막 값을 반환한다. - 보통 다음과 같은 query를 최적화 할때 호출된다.
SELECT * FROM t1 WHERE a=1 ORDER BY a DESC,b DESC;
23.16.11 Implementing the index_next() Method
- index scanning 을 할 때 호출된다.
int ha_foo::index_next(byte * buf)
buf는index_read()나index_first()같은 해당하는 다음 key에 매칭되는 row로 이동된 cursor에 의해 값을 채운다.
23.16.12 Implementing the index_prev() Method
- reverse index scanning 할때
index_prev()는 호출된다. buf는index_read()나index_last()같이 이전 key에 해당되는 row로 이동된 cursor에 의해 값을 채운다.
23.16.13 Implementing the index_next() Method
- index scanning 할때 호출되며,
buf는 index의 첫번째 값에 해당하는 row로 값을 채워진다.
int ha_foo::index_first(byte * buf)
23.16.14 Implementing the index_last() Method
- reverse index scanning 할때 호출되며,
buf는 index의 마지막 값에 해당하는 row로 값을 채운다.
int ha_foo::index_last(byte * buf)
23.17 Supporting Transactions
- Transaction을 지원하는 Storage Engine을 만들때 참조해야하는 내용
- transaction은 매우 복잡할수 있고, row versioning과 redo logs 같이 이 문서를 뛰어넘는 범위의 method를 포함한다.
- 모든 Method와 구현에 대한 설명이 아닌, 필수적인 내용에 국한되며, 구현의 예시는
ha_innodb.cc를 참조해라.
잠시
- 일단 Transaction을 구현하는 내용은 조금 나중에 다뤄야하는게 맞는 것 같다. 위에서 나온 내용으로 충분히 indexing 까지는 구현할수 있으니, 일단 구현하고 나중에 보자.
- 그리고 Transaction이 내용이 방대하니 미리 공부해놓고 여길 보는게 맞다.