The Design and Implementation of a Log-Structured File system
읽은 계기
주변에서 읽어보라 해서- F2FS 에서 관련 논문으로 조회되서
- 우연히 김박사넷에 관심 분야에 뭐뭐 있나 찾아보다가 보여서
잡담
- 겸사겸사 영어 공부할겸 영어로 paraphase 하면서 작문하는 연습을 하기로 했다.
- 영어로 먼적 작문 하고 한글로 다시 번역하는 식으로 진행
Abstract
- This paper introduces
log-structured file system. (이 논문에서는log-structured file system을 소개한다.) - This FS has a log-like structure and it contains all modifications sequentially. (이 파일 시스템에서는 log 같은 구조체가 있으며, 이건 모든 변경사항을 순차적으로 가지고 있다.)
- This method boosts file writing and crash recovery. (이러한 방법은 파일 쓰기와 장애 복구를 향상 시킨다.)
- The Log is a structure on disk to index information . (로그는 정보를 색인하기 위한 디스크 상의 자료구조이다.)
- We introduce new concepts, which disk spaces are divided by a specific size, to maintain large free areas on disk for fast writing. (빠른 쓰기를 위해 디스크에 큰 여유공간을 확보하는 게 문제가 되었고, 이를 디스크를 특정한 크기로 나눔으로써 해결하는 새로운 방법을 제시했다.)
- There is a prototype log-structured file system called Sprite LFS. It can use 70% of the disk bandwidth for writing. (Sprite LFS 라는 프로토 타입을 제시하였고, 이 는쓰기할때 디스크의 70%의 성능을 사용하게 해준다.)
1. Intorduction
Background
- CPU speeds have increased but disk doesn’t. => Application performances are limited. (CPU의 성능은 향상되는데 디스크는 그렇지 않고 이로 인해서 제약이 생긴다.)
Idea
- Many read requests loaded from main memory. => Write requests are a bottleneck on disk performances. (많은 읽기 요청이 메인 메모리에서 가져와지기 때문에 병목은 쓰기 요청에 있다는 것을 알수 있다.)
- Many of writing times account for seeking time. => We use a sequential structure called log to remove it. (쓰기 시간은 대부분이 쓸 위치를 찾는 시간이고, 이를 순차적 쓰기 구조를 통해서 해결한다.)
- Because of the nature of the log, crash recovery can be also faster. (Log 의 특성에 따라 자연스럽게 장애 복구 또한 빨라졌다.)
Related works
- Many other papers suggest this notion. But, it is only for temporary storage. (다른 논문들도 이런 개념을 제시하였으나 일시적 저장에 그쳤다.)
Well-known issues
- Log structured File system has a problem to free up disk space for new data. We solve it by introduce segments and segment cleaner. (알려진 문제로, Log structured File system은 새로운 데이터를 위해 디스크 공간을 확보하는 게 있으며, 이는 segments와 segment cleaner를 통해서 해결한다.)
2. Design for file systems of the 1990’s
2.1. Technology
- File system design has three significant components(Processors, Disks, and Main Memory).
- Disk performance depends on two components (Transfer bandwidth and access time).
- Disk is not better than before compared with CPU.
- Main Memory improvement is so remarkable that modern file systems cache recently-used file data in it. Therefore, a system can absorb a greater fraction of the read requests and more write requests can be buffered before write to disk.
2.2. Workloads
- Random accesses are dominated by small files. In contrast, Sequential are dominated by large file.
2.3. Problems with existing file systems
- Current file systems have two problems.
- First, spread information around the disk caused too many small accesses.
- Second, applications must wait for the write to complete.
3. Log-structured file systems
- Basic idea : Buffering a sequence of file system changes in the file cache and then writing all the changes to disk sequentially in a single disk write operations.
- This single write operation contains file data blocks, attributes, index, blocks, directories, and almost all the other information.
- This idea has two important issues.
- First, How to retrieve inforamtion from the log.
- Second, How to manage the free space on disk for writing new data.
3.1. File location and reading
- Basic structures are based from inode, and contains the first ten blocks of the file. When the file is bigger than ten blocks, it contains one or more indirect blocks.
- Unlike other file systems, inode map, which maintains the current locations of each inode, are placed at unfixed location. It is divided into log blocks.
- A fixed checkpoint region on each disk identifie the locations of all the inode map blocks.
3.2. Free space management: segments
- It is main issue for log-structured filesystem to manage free space.
- From this point on, Threading and copying live data are presented.
- Sprite LFS use a combination of threading and copying. -> The disk is divided into large fixed-size extent called segments.
- All live data are copied before the segment was rewritten.
3.3. Segment cleaning mechanism
- The process of copying live data out of a segment is called segment cleaning.
- It consists of three-step.
- Read a number of segments into memory
- Identify the live data
- Write the live data back to a smaller number of clean segments.
- In order to write out again, Identifying blocks must be possible.
- => For this purpose, We define segment summary block, which are indexing which segment is live.
- Segment Summary Blocks impose little overhead during writing, and they are useful during crash recovery.
- Sprite LFS counts the number (unique identifier - uid) to recognize which block is live. If the uid of a block does not match the uid currently stored in the inode map when the sgement is cleaned.
3.4. Segment cleaning policies
- Four policy issues must be addressed
- When should the segment cleaner execute?
- How many segments should it clean at a time?
- Which segments should be cleaned?
- How should the live blocks be grouped when they are written out?
- In this paper, we do not focus on the first and second keypoints. It just run when the number of segments which must be cleaned is over threadshold value.
- We think the third and fourth policy decisions are more important than former things.
- To decision this, we use a term called write cost
- \[\text{write cost} = \frac{\text{total bytes read and writeen}}{\text{new data written}} = \frac{\text{read segs} + \text{write live} + \text{write new}}{\text{new data written}} = \frac{N + N \times u + N \times (1-u)}{N \times (1-u)} = \frac{2}{1-u}\]
- It means the average amount of time when the disk is busy per byte of new data written, including all the cleaning overheads.
- It is ideal that this value equals 1.0.
- The above formula has one conservative assumption, a segment must be read in its entirety to recover the live blocks. However in practice, it may be faster to read just the live blocks.
- According to reference, Unix FFS on small-file workloads uses only at most 5-10% of the disk bandwidth for a write cost of 10-20.
- From this, we conclude the cleaner can choose the least utilized segments to clean.
- There is a trade off between performance and space utilization. But this is not only in log-structured file systems.
- The key for high performance at low cost is to force the disk into a bimodal segment distribution where some segments are nearly full and others are nearly empty.
3.5. Simulation results
- We build a simulator to analyze different cleaning policies under controlled conditions.
- modeling a fixed number of 4-kbytes files
- It has two random access patterns: Uniform and Hot-and-cold.
- Uniform : Each file has equal likelihood of being selected in each step.
- Hot-and-cold : One group contains 10% of the files; 90% of the time. The other are 90% of the files;10% of the time.
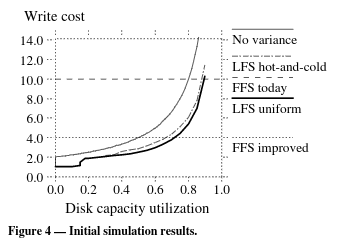
- Figure 4 shows the surprising result that locality and better grouping result in worse performance than a system with no locality.
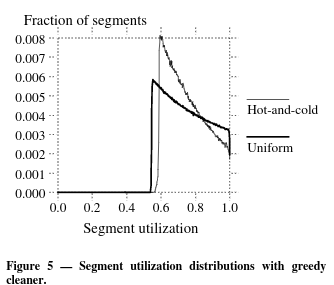
- Figure 5 shows the reason for above the situation. Every segment’s utilization eventually drops to the cleaning threshold, including the cold segments and the utilization of cold segments drops very slowly. It caused to linger.
- ??? 머지 이해 못하겠는데??
- 일단 지금 이해한건, cold data 도 live data 인데, 90% 정도로 큰 비율을 차지하기 때문에 segments 의 대부분이 live data 가 많은 채로 유지되고, 이게 결국 write cost를 커진 채로 남아 있는 block 들이 계속 쌓이게 되고, 이런 segments 들이 많아지다가 이걸 치워야 할때 문제가 발생한다는 건가?
3.6. Segment usage table
- It use
segment usage tableto support benefit. - Segment usage table maintains how many bytes of live data and most recent modified time per segment in order to clean.
- The blocks of the segment usage table are written to the log, and the addresses of the blocks are stored in the checkpoint regions.
4. Crash recovery
- When a system crash occurs, such as sudden shutdown, and reboot the system.
- In many other file system, Crash recovery has very high costs.
- However, Sprite LFS can improve this performance to use
checkpointsandroll-forward
4.1. Checkpoints
- To create a checkpoint, We have to take two steps.
- First, it writes out all modified information to the log, including file data blocks, indirect blocks, inodes, and blocks of the inode map and segment usage table.
- Second, it writes a checkpoint region to a special fixed position on disk.
- The checkpoint region contains the addresses of all the blocks in the inode map and segment usage table, plus the current time and a pointer to the last segment written.
- During reboot, Sprite LFS reads the checkpoint region and uses that information to initialize its main memory data strucutres.
- To prevent crash, there are actually two checkpoint regions for recovery.
- The checkpoint time determines which checkpoint to use for the recovery process.
- The interval between checkpoints affects the overhead of writing and system tolerance against crash. This paper use 30 seconds.
4.2. Roll-forward
- Crash recovery process is just to discard any data in the log after the lastest checkpoint. It named
roll-forward. - During roll-forward Sprite LFS uses the information in segment summary blocks to recovery recently-written file data.
- The roll-forward code also adjusts the utilizations in the segment usage table read from the checkpoint.
- The final issue in roll-forawrd is how to restore consistency between directory entries and inodes.
- To solve it, Sprite LFS outputs a special record in the log for each directory change(operation code, the location of the directory entry, the contents of the directory entry and the new reference count for the inode named in the entry.). - called the
directory operation log. - During roll-forward, the diretory operation log is used to ensure consistency between directory entries and inodes.
- The interaction between the directory operation log and checkpoints introduced additional synchronization issues.
5. Experience with the Sprite LFS
5.1. Micro-benchmarks
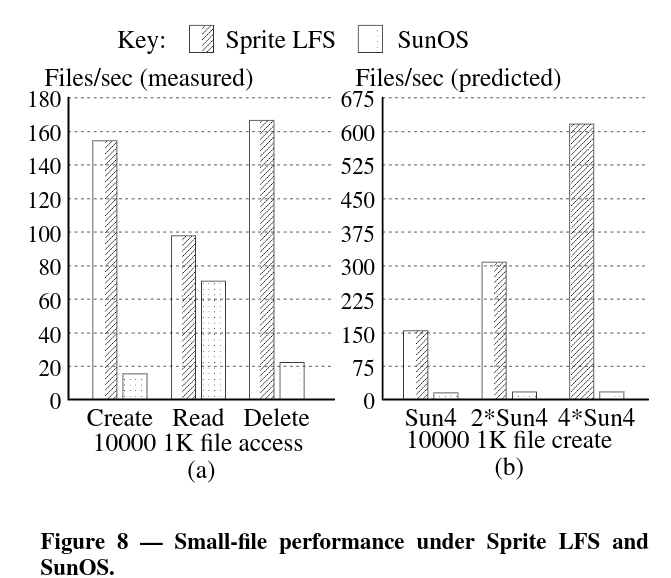
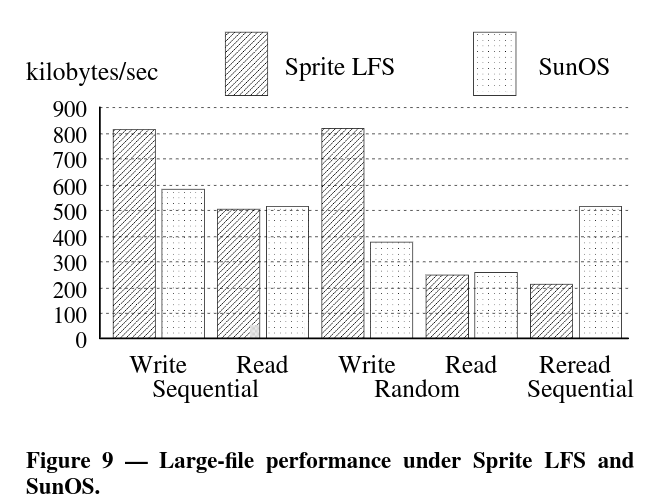
- 밴치마크를 지금 평가하기에는 조금 어려운듯. 논문 출판년도가 년도이고, 이때 당시에는 SSD 보다는 HDD 였을테니, 그냥 그랬구나하면서 끝내고, 논문에서 분석한 이유? 정도만 요약하면 될듯. 추가적으로 LFS의 뒤를 잇는 F2FS 를 다시 읽어보는게 더 좋을듯.
- The data is too old to analyze. We just see
Sprite LFSis better especially on writes.
5.2. Cleaning overheads
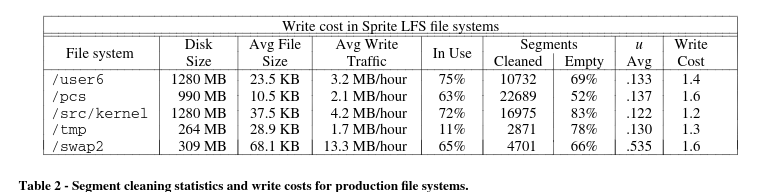
- 밴치마크들은 이야기하는 것 보다 그냥 보는게 낳은듯 더 이상 정리 안함.
- There are two reasons that the experience benchmarks is better than the simulations and predictions.
- First, in practice, there are a substantial number of longer files and they tend to be written and deleted as a whole, however in simulations, just a sing block long. It affects locality each segments.
- Second, data temperatures is different. In practice, it has much gap between hot data and cold data.
5.3. Crash recovery
- Skip
5.4. Other overheads in Sprite LFS
- Because of the short checkpoint interval, metadata is unnecessary often accessed.
6. Related work
- Skip
7. Conclusion
- The basic principle behind a lfs is “collect large amounts of new data in a file cache in main memory”.